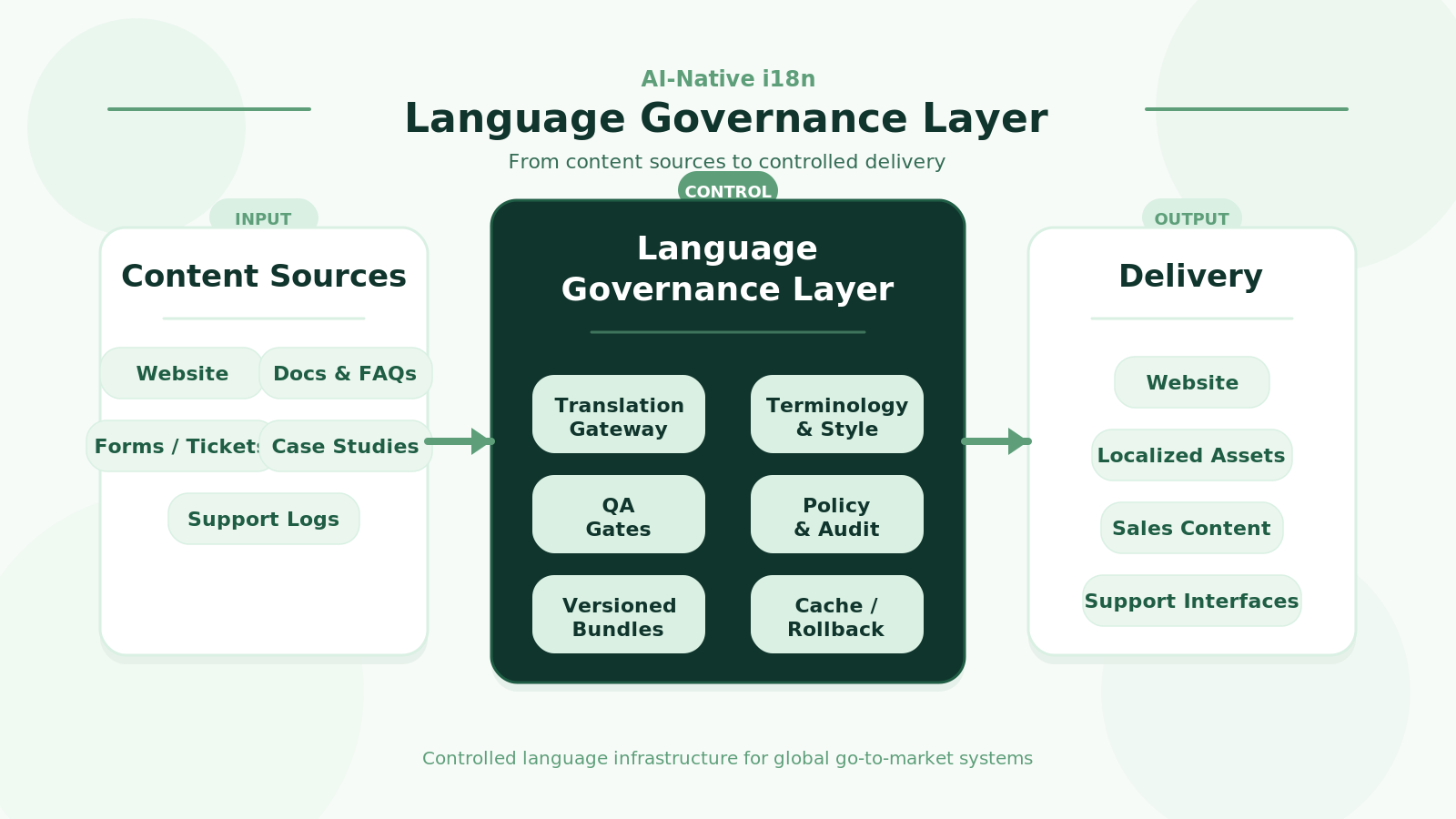
AI-native i18n sounds straightforward until it gets anywhere near production. On the surface, the story is familiar: faster translation, lower cost, better efficiency. But the moment the discussion gets close to real systems, the easy framing collapses. The real questions show up almost immediately: how versioning is handled, what gets cached, what rollback looks like, how terminology is enforced, where quality gets blocked before release, and where the compliance boundary really is. The moment i18n touches websites, documentation, FAQs, forms, case-study pages, or support entry points, it stops being a narrow translation topic.
In our own work around global go-to-market systems, we usually look at i18n as one part of a longer chain. It sits next to positioning, content, case studies, LinkedIn, and outbound. If the website shows product specs, sales talks about ROI, case studies talk about operational efficiency, and the localized versions use yet another vocabulary, the company may have translated its content, but the message still has not reached the market in a stable way. That is the problem I keep coming back to: once a complex product crosses markets, how do you keep the message consistent, intact, and usable instead of letting it fragment by channel and language?
There are already plenty of localization products with AI features. Looking at them from a production angle, though, most of them still sit in the translation-productivity layer. That is useful, but it is still some distance away from what I would call a full AI-native i18n system. The question I keep coming back to is simpler and more structural: can the language layer itself be treated like a system? Can it be cached, rolled back, audited, budgeted, and governed with a clear compliance boundary? Once I frame it that way, I stop caring so much about “which model should we pick” and start caring much more about “where does the system boundary sit, what do we need to own, and what should remain outside.”
Runtime Translation Is Not the System
A common way this topic gets distorted is by reducing AI-native i18n to runtime translation for every page. That idea works in demos. In production, it runs into constraints very quickly. Per-request translation ties latency, cost, and availability directly to external model services. Any instability upstream becomes user-facing. Content such as pricing, warranty language, safety notes, privacy text, and support commitments also needs stable versions, clear provenance, and traceable history. Then there is the next step: once forms, chats, tickets, or device logs enter the same system, the problem expands into data processing, and compliance moves into the application architecture. From a production perspective, the more useful discussion is about building a controllable language layer. Real-time generation is only one piece inside that picture.
For websites, a relatively safe pattern is to default to published resources and let AI handle incremental work rather than the full read path. The stable layer is still the usual i18n stack: ICU MessageFormat, CLDR, locale routing, versioned bundles, CDN delivery, and caching. AI sits on top of that layer. In practice it usually handles three types of work: generating translations for newly added content, filling controlled cache misses, and evaluating or repairing existing translations. As long as the default path stays on published resources, the cost model and the risk model stay much easier to reason about. It may not sound aggressive, but it directly affects whether later content systems, sales materials, and outbound assets can keep using one consistent language system.
Quality Needs Gates Before Release
Quality control is another part that is easy to underestimate. In many traditional translation workflows, human review exists, but it is pushed too far downstream and does not scale well. If AI-native i18n only increases generation speed and leaves quality where it was, the system simply produces errors faster. In practice, teams usually need several gates before release. A rule-based gate checks placeholders, HTML tags, numbers, units, links, and ICU patterns. A terminology and style gate ensures brand terms, product terms, and legally sensitive wording are not freely rewritten by the model. A risk-based gate then decides which pages need mandatory human review, which pages can be sampled after AI generation, and which pages can move through a more automated path. The important part here is not the existence of a score by itself. The important part is what score blocks release, and which page categories never pass automatically.
Context Has to Travel with the Request
Context is just as important. A large share of translation failures come from weak input. If a model only receives one sentence, it can only guess. In production, several kinds of context usually need to travel with the request: page context, structural context, asset context, and risk context. This matters even more for industrial products, because the same term can carry different expectations across a product page, a case study, a distributor handbook, and a support document. When context is missing, AI falls back to behaving like a generic translator. As context accumulates, it starts behaving more like part of the language layer.
Cost Only Becomes Real Once It Can Be Budgeted
Cost is also often discussed too vaguely. For websites, the more useful metrics are content delta, cache hit rate, bundle release frequency, and the share of traffic that still triggers external inference. Most translation services charge by characters, input/output volume, or target languages. That means the more useful engineering objective is to reduce unnecessary calls. A few practical measures usually help immediately: cache at the segment level rather than at the page level; include source hash, locale, terminology version, style version, and model profile in the cache key; decouple translation jobs from page reads so newly added content goes through a queue instead of the main request path; and fall back to the previous published version when upstream services fail. Once these pieces are in place, cost becomes something that can be budgeted rather than guessed.
Compliance Belongs Inside the Architecture
Compliance is another area that rarely benefits from being deferred. If the system may touch personal information, contact details, support tickets, chat logs, or any content that can be tied back to a user, device, or order, the language layer starts acting as a data-processing layer. At that point a policy layer becomes necessary. Some content may go to an offshore model, some may require regional handling, some may need redaction first, some may only allow controlled changes inside a fixed template, and some may need to stay in-region by default. Those decisions are much easier to manage when they are turned into request parameters and system rules. They are much harder to manage when they depend on whoever happens to be shipping the page that day.
Start with a Governance Layer
Given all of that, the technical path does not look especially exotic to me. I would usually start with a mature i18n foundation plus existing TMS, MT, and LLM services, then add a lightweight governance layer on top. That governance layer does not need to look like a full platform on day one. A first version can stay pretty small: one translation gateway in front of external services, segment-level cache and versioned bundles, a set of QA checks, a terminology and style layer, an audit log, and a minimal policy layer. Once those pieces are in place, the team is no longer just using translation tools. It has started to own a real language-governance capability.
If that governance layer is broken down further, the interface surface is usually manageable. A translation endpoint handles single and batch requests with context, terminology, style, and risk metadata attached. A publishing endpoint creates and serves locale bundles by version. A quality endpoint runs checks, blocks low-confidence outputs, and accepts human-review feedback. A policy endpoint determines what can use external models and what must stay on fixed templates or regional paths. Without these entry points, systems tend to decay into a loose collection of tools, and the maintenance burden climbs quickly.
Roll It Out in Phases
There is also no real need to force everything into one release cycle. A first phase can stay focused on a small PoC across three to six core languages, mainly to validate terminology control, versioned release, human gating, and rollback. A second phase can introduce hybrid productionization by adding the translation gateway, cache, audit trail, and risk segmentation. A third phase can wait until scale really justifies it: internal editors, vendor management, quality dashboards, or multimodal pipelines. Full platformization only starts to make sense when content volume, language count, compliance pressure, and vendor lock-in risk all rise together.
Different Content Types Need Different Rules
One more boundary is worth keeping in view. AI-native i18n is really a discussion about how models enter a bounded system. Some content types can support high automation. Others cannot. Blog posts, news updates, and campaign pages usually tolerate a high degree of automation. Product pages, FAQs, and case studies often need a semi-automated path. Pricing, safety language, legal text, warranty terms, privacy notices, and support commitments usually need strong review and version locking. The job of the system is to classify these layers and apply different handling rules. When that classification is done well, i18n can share terminology and expression with positioning, content, and outbound. When it is done badly, localization drifts toward multi-language duplication.
What I Keep Paying Attention To
The areas I keep paying attention to are fairly consistent: runtime stability, quality gating, context completeness, cost control, and explainable compliance boundaries. Until those constraints have been systematized, AI-native i18n still looks to me like translation workflows with AI layered on top. Once those constraints start moving into the system itself, even a stack built on external platforms and external models starts looking a lot more real. For a company like Intelliexport.ai, this matters beyond translation. It shapes whether a complex product can be explained clearly across markets, carried consistently through the funnel, and understood well enough to be bought.